Glide的作用官网https://github.com/bumptech/glide已经做了很明确的说明了。简单总结就是用它来加载图片会很丝滑,几乎能满足你对图片的读取/缩放/显示的一切需求。性能方面,它兼顾了图片的解码速度以及图片的解码带来的资源压力。
我们可以思考下,如果让我们自己来实现图片加载框架,需要考虑哪些方面呢?
1.图片下载是个耗时过程,我们首先需要考虑的就是图片缓存的问题。
2.图片加载也是个耗内存的操作,很多OOM都是图片加载导致的,所以我们也要考虑内存优化问题。
3.图片加载到一半,页面关闭了,图片加载也应该中止,这又牵扯到了生命周期管理的问题。
4.还有就是图片加载框架是否支持大图加载?大图情况下会有什么问题?
本文就针对以上问题,结合源码来剖析Glide是如何做到以上几点的。
1 整体架构
先借用网络上一张图,从整体上先了解Glide加载图片的全过程。
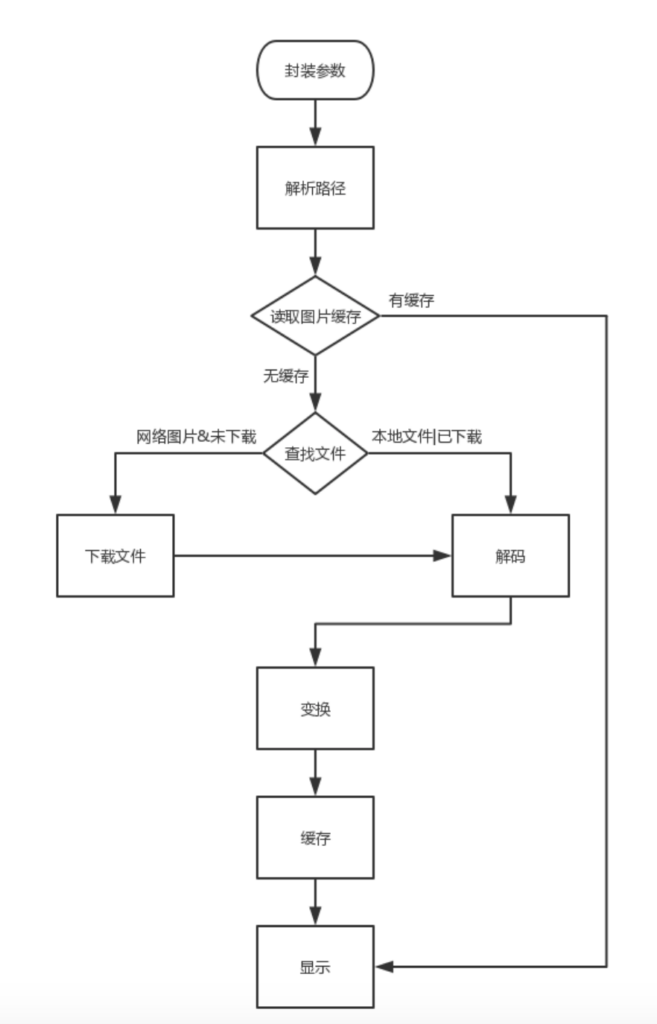
1.封装参数:从指定来源,到输出结果,中间可能经历很多流程,所以第一件事就是封装参数,这些参数会贯穿整个过程;
2.解析路径:图片的来源有多种,格式也不尽相同,需要规范化;
3.读取缓存:为了减少计算,通常都会做缓存;同样的请求,从缓存中取图片(Bitmap)即可;
4.查找文件/下载文件:如果是本地的文件,直接解码即可;如果是网络图片,需要先下载;
5.解码:这一步是整个过程中最复杂的步骤之一,有不少细节;
6.变换:解码出Bitmap之后,可能还需要做一些变换处理(圆角,滤镜等);
7.缓存:得到最终bitmap之后,可以缓存起来,以便下次请求时直接取结果;
8.显示:显示结果,可能需要做些动画(淡入动画,crossFade等)。
Glide用法很简单,一行代码就能搞定从网络加载图片并显示出来。
Glide.with(this).load(url).into(imageView)
接下来就结合源码分别对with、load、into方法来做解析。
2 with方法
在分析源码之前,我们先看下Glide.with的时序图,看下代码的调用过程,这样我们对with的整个流程就有一个宏观的了解。
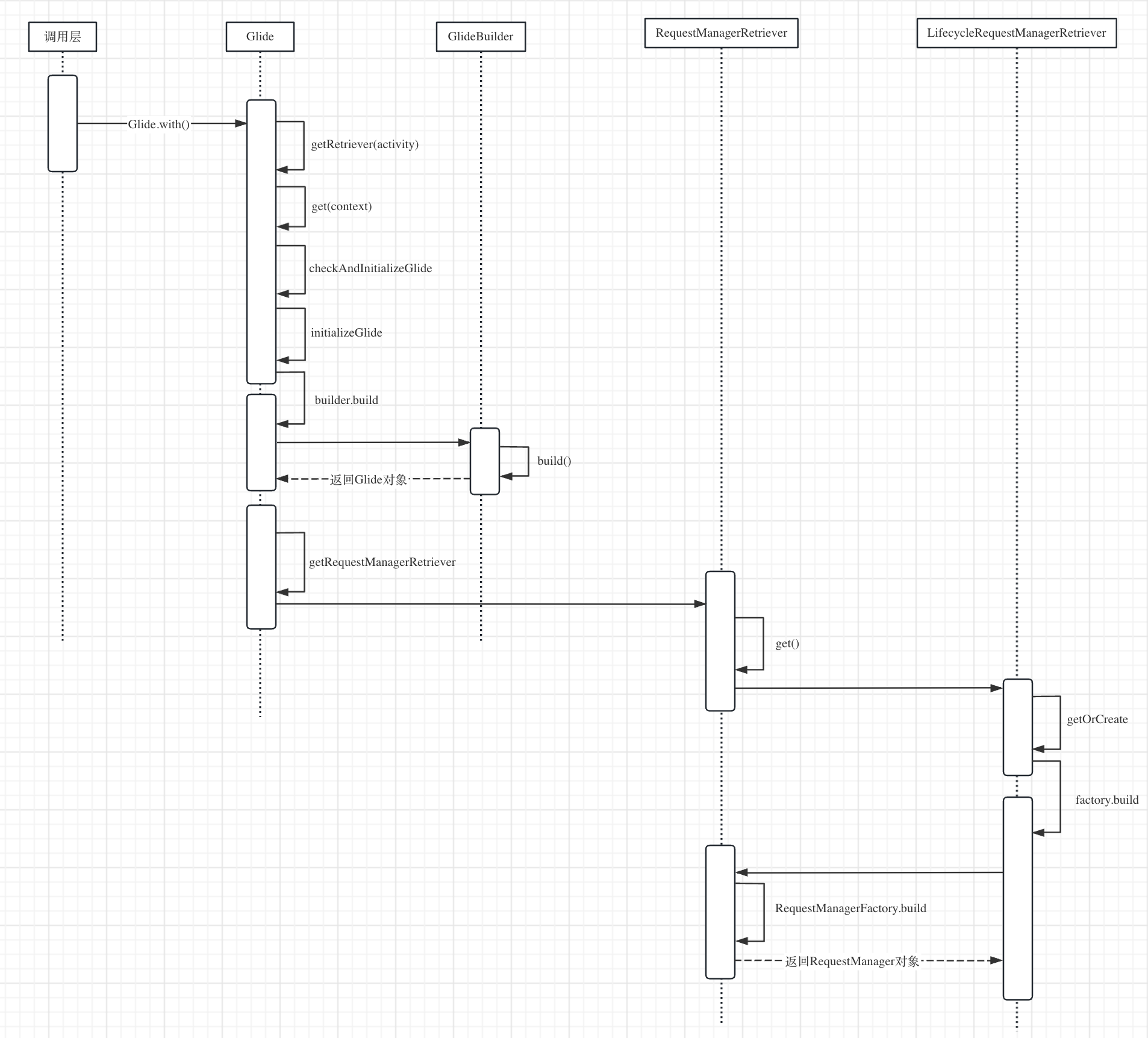
上面涉及到几个类:
1.Glide:用来做一些初始化的工作,持有缓存、各种线程池、Engine等。
2.GlideBuilder:创建Glide,初始化缓存、各种线程池、Engine等。
3.RequestManagerRetriever:创建并管理RequestManager。
4.LifecycleRequestManagerRetriever:生命周期的管理。
5.RequestManager:图片请求的管理。
接下来看下几个关键的源码,首先是Glide类:
public class Glide {
public static RequestManager with(@NonNull FragmentActivity activity) {
return getRetriever(activity).get(activity);
}
private static RequestManagerRetriever getRetriever(@Nullable Context context) {
return Glide.get(context).getRequestManagerRetriever();
}
public static Glide get(@NonNull Context context) {
if (glide == null) {
GeneratedAppGlideModule annotationGeneratedModule =
getAnnotationGeneratedGlideModules(context.getApplicationContext());
synchronized (Glide.class) {
if (glide == null) {
checkAndInitializeGlide(context, annotationGeneratedModule);
}
}
}
return glide;
}
static void checkAndInitializeGlide(
@NonNull Context context, @Nullable GeneratedAppGlideModule generatedAppGlideModule) {
initializeGlide(context, generatedAppGlideModule);
}
private static void initializeGlide(
@NonNull Context context,
@NonNull GlideBuilder builder,
@Nullable GeneratedAppGlideModule annotationGeneratedModule) {
Glide glide = builder.build(applicationContext, manifestModules, annotationGeneratedModule);
Glide.glide = glide;
}
public RequestManagerRetriever getRequestManagerRetriever() {
return requestManagerRetriever;
}
}
核心功能主要是通过GlideBuilder.build创建Glide。
再看看GlideBuilder类:
public final class GlideBuilder {
private Engine engine;
private BitmapPool bitmapPool;
private ArrayPool arrayPool;
private MemoryCache memoryCache;
private GlideExecutor sourceExecutor;
private GlideExecutor diskCacheExecutor;
private DiskCache.Factory diskCacheFactory;
private MemorySizeCalculator memorySizeCalculator;
Glide build(
@NonNull Context context,
List<GlideModule> manifestModules,
AppGlideModule annotationGeneratedGlideModule) {
if (sourceExecutor == null) {
sourceExecutor = GlideExecutor.newSourceExecutor();
}
if (diskCacheExecutor == null) {
diskCacheExecutor = GlideExecutor.newDiskCacheExecutor();
}
if (animationExecutor == null) {
animationExecutor = GlideExecutor.newAnimationExecutor();
}
if (memorySizeCalculator == null) {
memorySizeCalculator = new MemorySizeCalculator.Builder(context).build();
}
if (connectivityMonitorFactory == null) {
connectivityMonitorFactory = new DefaultConnectivityMonitorFactory();
}
if (bitmapPool == null) {
int size = memorySizeCalculator.getBitmapPoolSize();
if (size > 0) {
bitmapPool = new LruBitmapPool(size);
} else {
bitmapPool = new BitmapPoolAdapter();
}
}
if (arrayPool == null) {
arrayPool = new LruArrayPool(memorySizeCalculator.getArrayPoolSizeInBytes());
}
if (memoryCache == null) {
memoryCache = new LruResourceCache(memorySizeCalculator.getMemoryCacheSize());
}
if (diskCacheFactory == null) {
diskCacheFactory = new InternalCacheDiskCacheFactory(context);
}
if (engine == null) {
engine =
new Engine(
memoryCache,
diskCacheFactory,
diskCacheExecutor,
sourceExecutor,
GlideExecutor.newUnlimitedSourceExecutor(),
animationExecutor,
isActiveResourceRetentionAllowed);
}
if (defaultRequestListeners == null) {
defaultRequestListeners = Collections.emptyList();
} else {
defaultRequestListeners = Collections.unmodifiableList(defaultRequestListeners);
}
GlideExperiments experiments = glideExperimentsBuilder.build();
RequestManagerRetriever requestManagerRetriever =
new RequestManagerRetriever(requestManagerFactory, experiments);
return new Glide(
context,
engine,
memoryCache,
bitmapPool,
arrayPool,
requestManagerRetriever,
connectivityMonitorFactory,
logLevel,
defaultRequestOptionsFactory,
defaultTransitionOptions,
defaultRequestListeners,
manifestModules,
annotationGeneratedGlideModule,
experiments);
}
}
真正创建Glide的地方,还有一些后续加载以及显示图片时会用到的各种线程池等。
再看看RequestManagerRetriever类,贴出一些关键代码:
public class RequestManagerRetriever {
public RequestManagerRetriever(
@Nullable RequestManagerFactory factory, GlideExperiments experiments) {
this.factory = factory != null ? factory : DEFAULT_FACTORY;
}
public RequestManager get(@NonNull FragmentActivity activity) {
if (Util.isOnBackgroundThread()) {
return get(activity.getApplicationContext());
}
assertNotDestroyed(activity);
frameWaiter.registerSelf(activity);
boolean isActivityVisible = isActivityVisible(activity);
Glide glide = Glide.get(activity.getApplicationContext());
return lifecycleRequestManagerRetriever.getOrCreate(
activity,
glide,
activity.getLifecycle(),
activity.getSupportFragmentManager(),
isActivityVisible);
}
public RequestManager get(@NonNull Fragment fragment) {
......
return lifecycleRequestManagerRetriever.getOrCreate(
context, glide, fragment.getLifecycle(), fm, fragment.isVisible());
}
public RequestManager get(@NonNull Activity activity) {
return fragmentGet(activity, fm, /* parentHint= */ null, isActivityVisible(activity));
}
private RequestManager fragmentGet(
@NonNull Context context,
@NonNull FragmentManager fm,
@Nullable Fragment parentHint,
boolean isParentVisible) {
RequestManagerFragment current = getRequestManagerFragment(fm, parentHint);
RequestManager requestManager =
factory.build(
glide, current.getGlideLifecycle(), current.getRequestManagerTreeNode(), context);
return requestManager;
}
private static final RequestManagerFactory DEFAULT_FACTORY =
RequestManagerFactory() {
@NonNull
@Override
public RequestManager build(
@NonNull Glide glide,
@NonNull Lifecycle lifecycle,
@NonNull RequestManagerTreeNode requestManagerTreeNode,
@NonNull Context context) {
return new RequestManager(glide, lifecycle, requestManagerTreeNode, context);
}
};
}
可以看到有多个get重载方法,常用的也就三个get(FragmentActivity)、get(Context)、get(Fragment),至于get(Activity),一般我们的XXXActivity很少直接继承自Activity,所以这个方法基本也快废弃了。当然抱着学习的目的,可以大概了解下,这里面的核心就是创建一个没有界面的RequestManagerFragment,让Glide同Fragment生命周期绑定在一起。
最后再看看LifecycleRequestManagerRetriever,看名字也知道这个是管理生命周期和RequestManager的。
final class LifecycleRequestManagerRetriever {
@Synthetic final Map<Lifecycle, RequestManager> lifecycleToRequestManager = new HashMap<>();
@NonNull private final RequestManagerFactory factory;
LifecycleRequestManagerRetriever(@NonNull RequestManagerFactory factory) {
this.factory = factory;
}
RequestManager getOnly(Lifecycle lifecycle) {
Util.assertMainThread();
return lifecycleToRequestManager.get(lifecycle);
}
RequestManager getOrCreate(
Context context,
Glide glide,
final Lifecycle lifecycle,
FragmentManager childFragmentManager,
boolean isParentVisible) {
Util.assertMainThread();
RequestManager result = getOnly(lifecycle);
if (result == null) {
LifecycleLifecycle glideLifecycle = new LifecycleLifecycle(lifecycle);
result =
factory.build(
glide,
glideLifecycle,
new SupportRequestManagerTreeNode(childFragmentManager),
context);
lifecycleToRequestManager.put(lifecycle, result);
glideLifecycle.addListener(
new LifecycleListener() {
@Override
public void onStart() {}
@Override
public void onStop() {}
@Override
public void onDestroy() {
lifecycleToRequestManager.remove(lifecycle);
}
});
// This is a bit of hack, we're going to start the RequestManager, but not the
// corresponding Lifecycle. It's safe to start the RequestManager, but starting the
// Lifecycle might trigger memory leaks. See b/154405040
if (isParentVisible) {
result.onStart();
}
}
return result;
}
}
getOrCreate()方法首先创建LifecycleLifecycle,这个类里面使用lifecycle.addObserver(this)来注册生命周期监听,然后将生命周期各阶段调用到的方法再回调给传进来的LifecycleListener。
接着调用factory.build()创建RequestManager,这里的factory大家阅读源码会发现就是RequestManagerRetriever里面的DEFAULT_FACTORY。
注意RequestManager创建时传入的参数lifecycle,也就是刚刚创建的LifecycleLifecycle glideLifecycle = xxx。接下来RequestManager里面会调用lifecycle.addListener来注册监听。
public class RequestManager implements ComponentCallbacks2, LifecycleListener, ModelTypes<RequestBuilder<Drawable>> {
final Lifecycle lifecycle;
@GuardedBy("this")
private final RequestTracker requestTracker;
@GuardedBy("this")
private final RequestManagerTreeNode treeNode;
@GuardedBy("this")
private final TargetTracker targetTracker = new TargetTracker();
RequestManager(
Glide glide,
Lifecycle lifecycle,
RequestManagerTreeNode treeNode,
RequestTracker requestTracker,
ConnectivityMonitorFactory factory,
Context context) {
this.glide = glide;
this.lifecycle = lifecycle;
this.treeNode = treeNode;
this.requestTracker = requestTracker;
this.context = context;
connectivityMonitor =
factory.build(
context.getApplicationContext(),
new RequestManagerConnectivityListener(requestTracker));
// Order matters, this might be unregistered by teh listeners below, so we need to be sure to
// register first to prevent both assertions and memory leaks.
glide.registerRequestManager(this);
// If we're the application level request manager, we may be created on a background thread.
// In that case we cannot risk synchronously pausing or resuming requests, so we hack around the
// issue by delaying adding ourselves as a lifecycle listener by posting to the main thread.
// This should be entirely safe.
if (Util.isOnBackgroundThread()) {
Util.postOnUiThread(addSelfToLifecycle);
} else {
lifecycle.addListener(this);
}
lifecycle.addListener(connectivityMonitor);
defaultRequestListeners =
new CopyOnWriteArrayList<>(glide.getGlideContext().getDefaultRequestListeners());
setRequestOptions(glide.getGlideContext().getDefaultRequestOptions());
}
/**
* Lifecycle callback that registers for connectivity events (if the
* android.permission.ACCESS_NETWORK_STATE permission is present) and restarts failed or paused
* requests.
*/
@Override
public synchronized void onStart() {
resumeRequests();
targetTracker.onStart();
}
/**
* Lifecycle callback that unregisters for connectivity events (if the
* android.permission.ACCESS_NETWORK_STATE permission is present) and pauses in progress loads.
*/
@Override
public synchronized void onStop() {
pauseRequests();
targetTracker.onStop();
}
/**
* Lifecycle callback that cancels all in progress requests and clears and recycles resources for
* all completed requests.
*/
@Override
public synchronized void onDestroy() {
targetTracker.onDestroy();
for (Target<?> target : targetTracker.getAll()) {
clear(target);
}
targetTracker.clear();
requestTracker.clearRequests();
lifecycle.removeListener(this);
lifecycle.removeListener(connectivityMonitor);
Util.removeCallbacksOnUiThread(addSelfToLifecycle);
glide.unregisterRequestManager(this);
}
}
可以看到构造方法里面注册了生命周期的监听,比如onStart、onStop、onDestroy生命周期方法里面对请求和Target做了处理。这样在RequestManager里面就将Glide与Fragment或者FragmentActivity的生命周期绑定到一块了。
with的整个流程还是挺复杂的,其主要目的就是线程池 、 缓存 、 请求管理、生命周期绑定以及其它配置初始化的构建。接下来我们看看load都做了些啥。
3 load方法
先看下load过程的时序图:
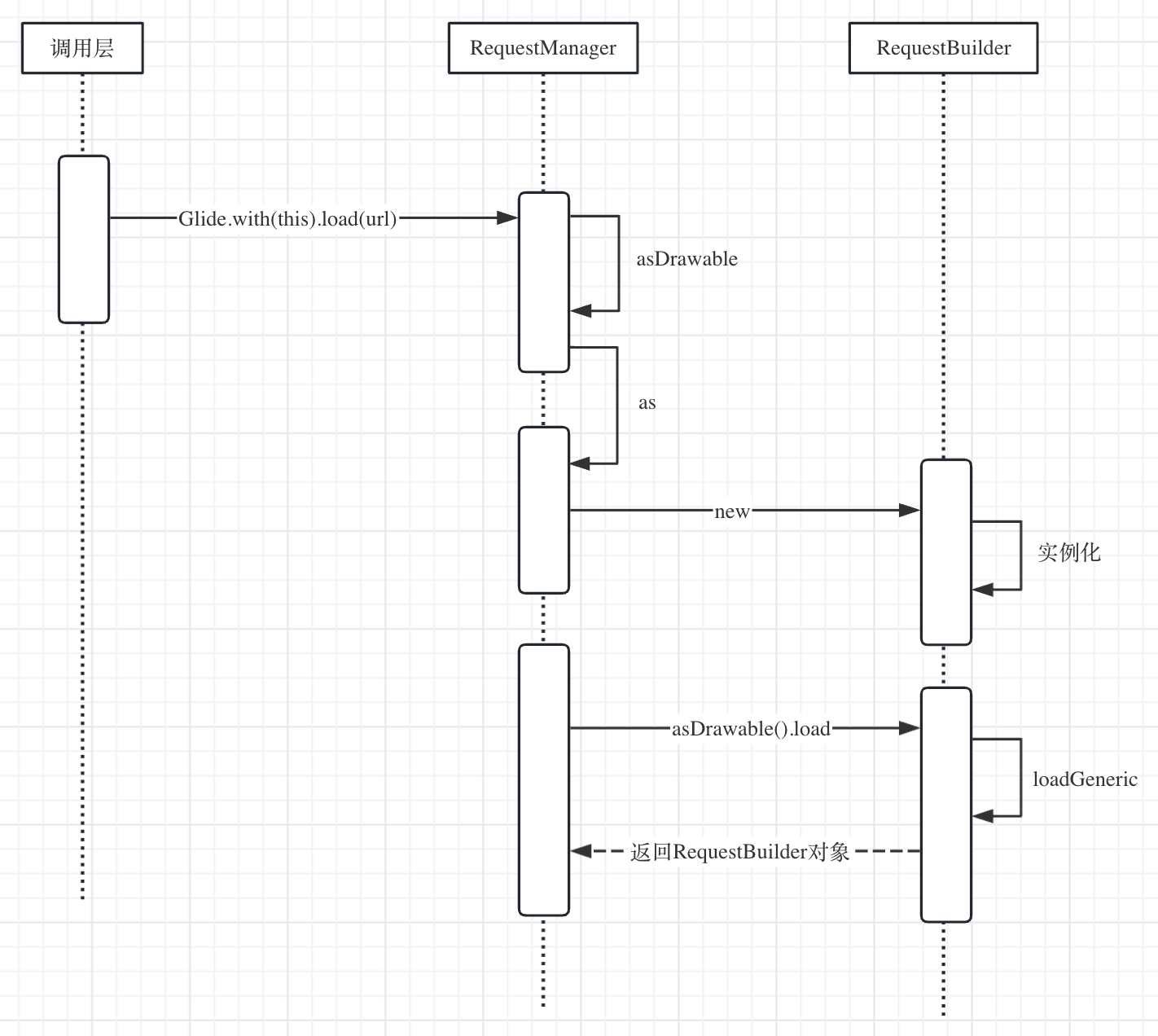
load根据with创建的RequestManager来创建RequestBuilder,简单的看下涉及到的RequestManager的源码:
public class RequestManager
implements ComponentCallbacks2, LifecycleListener, ModelTypes<RequestBuilder<Drawable>> {
@Override
public RequestBuilder<Drawable> load(@Nullable String string) {
return asDrawable().load(string);
}
public RequestBuilder<Drawable> asDrawable() {
return as(Drawable.class);
}
public <ResourceType> RequestBuilder<ResourceType> as(
@NonNull Class<ResourceType> resourceClass) {
return new RequestBuilder<>(glide, this, resourceClass, context);
}
}
RequestBuilder类的内部重载了很多load方法,比如加载Uri、加载本地File。由于篇幅有限,这里就不贴源码了。
最后我们来一起看下into方法,这个方法启动整个调用链,获取到资源后设置给ImageView。
4 into方法
into方法的调用过程非常复杂,理解和整理逻辑关系断断续续就花了几天的时间。因为Glide是一个功能非常全的图片、动画加载框架,它要兼容处理很多种场景,比如图像的圆角处理、转场动画、加载网络图片、加载本地图片、处理缓存等等。
其实再复杂的问题,我们都可以拆解成一个个小的问题去剖析。接下来我们就一起来探究下Glide的into方法。
由于涉及的类和方法太多,我把into整个过程分为三个部分来讲解。
(1)首先会分析下整体的流程。
(2)然后再分析DecodeHelper.getLoadData,该方法根据加载的内容以及需要的数据源类型决定采用哪种方式来加载资源。
(3)最后再分析decodeFromFetcher,这一步决定采用哪种方式来解析第2步返回的数据。
4.1 整体流程
图太大了,贴出来没法看,大图直接看附件。
public ViewTarget<ImageView, TranscodeType> into(@NonNull ImageView view) {
Util.assertMainThread();
Preconditions.checkNotNull(view);
//根据ImageView布局中设置的scaleType来创建requestOptions
BaseRequestOptions<?> requestOptions = this;
if (!requestOptions.isTransformationSet()
&& requestOptions.isTransformationAllowed()
&& view.getScaleType() != null) {
// Clone in this method so that if we use this RequestBuilder to load into a View and then
// into a different target, we don't retain the transformation applied based on the previous
// View's scale type.
switch (view.getScaleType()) {
case CENTER_CROP:
requestOptions = requestOptions.clone().optionalCenterCrop();
break;
case CENTER_INSIDE:
requestOptions = requestOptions.clone().optionalCenterInside();
break;
case FIT_CENTER:
case FIT_START:
case FIT_END:
requestOptions = requestOptions.clone().optionalFitCenter();
break;
case FIT_XY:
requestOptions = requestOptions.clone().optionalCenterInside();
break;
case CENTER:
case MATRIX:
default:
// Do nothing.
}
}
return into(
//创建ViewTarget
glideContext.buildImageViewTarget(view, transcodeClass),
/* targetListener= */ null,
requestOptions,
Executors.mainThreadExecutor());
}
这一步比较简单,主要三个目的:
(1)根据scaleType创建requestOptions。
(2)调用重载的into方法。
(3)根据view以及transcodeClass创建ViewTarget。
重点看下第3个,view就是我们传入的ImageView,transcodeClass参数我们可以看下上一节讲load的时候贴出来的RequestManager源码,其实就是Drawable.class。
public class ImageViewTargetFactory {
@NonNull
@SuppressWarnings("unchecked")
public <Z> ViewTarget<ImageView, Z> buildTarget(
@NonNull ImageView view, @NonNull Class<Z> clazz) {
if (Bitmap.class.equals(clazz)) {
return (ViewTarget<ImageView, Z>) new BitmapImageViewTarget(view);
} else if (Drawable.class.isAssignableFrom(clazz)) {
return (ViewTarget<ImageView, Z>) new DrawableImageViewTarget(view);
} else {
throw new IllegalArgumentException(
"Unhandled class: " + clazz + ", try .as*(Class).transcode(ResourceTranscoder)");
}
}
}
由此可知,在本例中,返回的ViewTarget其实就是DrawableImageViewTarget。
接着再看上面提到的into重载方法:
private <Y extends Target<TranscodeType>> Y into(
@NonNull Y target,
@Nullable RequestListener<TranscodeType> targetListener,
BaseRequestOptions<?> options,
Executor callbackExecutor) {
...
Request request = buildRequest(target, targetListener, options, callbackExecutor);
requestManager.track(target, request);
...
}
重点关注下两点:
(1)buildRequest创建Request。
(2)track执行请求。
buildRequest对照源码一步步往下跟,最终调用SingleRequest.obtain返回SingleRequest,因为比较简单,源码就不贴了。
track方法我们往下跟几步会发现调用了request.begin,request就是上面提到的SingleRequest。
@Override
public void begin() {
synchronized (requestLock) {
...
// If we're restarted after we're complete (usually via something like a notifyDataSetChanged
// that starts an identical request into the same Target or View), we can simply use the
// resource and size we retrieved the last time around and skip obtaining a new size, starting
// a new load etc. This does mean that users who want to restart a load because they expect
// that the view size has changed will need to explicitly clear the View or Target before
// starting the new load.
if (status == Status.COMPLETE) {
onResourceReady(
resource, DataSource.MEMORY_CACHE, /* isLoadedFromAlternateCacheKey= */ false);
return;
}
if (Util.isValidDimensions(overrideWidth, overrideHeight)) {
onSizeReady(overrideWidth, overrideHeight);
} else {
target.getSize(this);
}
if ((status == Status.RUNNING || status == Status.WAITING_FOR_SIZE)
&& canNotifyStatusChanged()) {
target.onLoadStarted(getPlaceholderDrawable());
}
...
}
}
当获取到view的宽高后,走到onSizeReady。
@Override
public void onSizeReady(int width, int height) {
...
loadStatus =
engine.load(
glideContext,
model,
requestOptions.getSignature(),
this.width,
this.height,
requestOptions.getResourceClass(),
transcodeClass,
priority,
requestOptions.getDiskCacheStrategy(),
requestOptions.getTransformations(),
requestOptions.isTransformationRequired(),
requestOptions.isScaleOnlyOrNoTransform(),
requestOptions.getOptions(),
requestOptions.isMemoryCacheable(),
requestOptions.getUseUnlimitedSourceGeneratorsPool(),
requestOptions.getUseAnimationPool(),
requestOptions.getOnlyRetrieveFromCache(),
this,
callbackExecutor);
...
}
接着调用Engine的load方法:
public <R> LoadStatus load(
GlideContext glideContext,
Object model,
Key signature,
int width,
int height,
Class<?> resourceClass,
Class<R> transcodeClass,
Priority priority,
DiskCacheStrategy diskCacheStrategy,
Map<Class<?>, Transformation<?>> transformations,
boolean isTransformationRequired,
boolean isScaleOnlyOrNoTransform,
Options options,
boolean isMemoryCacheable,
boolean useUnlimitedSourceExecutorPool,
boolean useAnimationPool,
boolean onlyRetrieveFromCache,
ResourceCallback cb,
Executor callbackExecutor) {
long startTime = VERBOSE_IS_LOGGABLE ? LogTime.getLogTime() : 0;
//拿到缓存或者请求的key
EngineKey key =
keyFactory.buildKey(
model,
signature,
width,
height,
transformations,
resourceClass,
transcodeClass,
options);
EngineResource<?> memoryResource;
synchronized (this) {
memoryResource = loadFromMemory(key, isMemoryCacheable, startTime);
if (memoryResource == null) {
return waitForExistingOrStartNewJob(
glideContext,
model,
signature,
width,
height,
resourceClass,
transcodeClass,
priority,
diskCacheStrategy,
transformations,
isTransformationRequired,
isScaleOnlyOrNoTransform,
options,
isMemoryCacheable,
useUnlimitedSourceExecutorPool,
useAnimationPool,
onlyRetrieveFromCache,
cb,
callbackExecutor,
key,
startTime);
}
}
// Avoid calling back while holding the engine lock, doing so makes it easier for callers to
// deadlock.
cb.onResourceReady(
memoryResource, DataSource.MEMORY_CACHE, /* isLoadedFromAlternateCacheKey= */ false);
return null;
}
private EngineResource<?> loadFromMemory(
EngineKey key, boolean isMemoryCacheable, long startTime) {
if (!isMemoryCacheable) {
return null;
}
EngineResource<?> active = loadFromActiveResources(key);
if (active != null) {
if (VERBOSE_IS_LOGGABLE) {
logWithTimeAndKey("Loaded resource from active resources", startTime, key);
}
return active;
}
EngineResource<?> cached = loadFromCache(key);
if (cached != null) {
if (VERBOSE_IS_LOGGABLE) {
logWithTimeAndKey("Loaded resource from cache", startTime, key);
}
return cached;
}
return null;
}
先调用loadFromMemory,该方法内部的loadFromActiveResources是从活动缓存中获取数据,loadFromCache是从内存缓存中获取数据。关于缓存,回头再单独写一篇文章来讲解。如果缓存中没有数据,接着调用waitForExistingOrStartNewJob:
private <R> LoadStatus waitForExistingOrStartNewJob() {
EngineJob<R> engineJob = engineJobFactory.build(xxx);
DecodeJob<R> decodeJob = decodeJobFactory.build(xxx);
engineJob.start(decodeJob);
return new LoadStatus(cb, engineJob);
}
class EngineJob<R> implements DecodeJob.Callback<R>, Poolable {
...
public synchronized void start(DecodeJob<R> decodeJob) {
this.decodeJob = decodeJob;
GlideExecutor executor =
decodeJob.willDecodeFromCache() ? diskCacheExecutor : getActiveSourceExecutor();
executor.execute(decodeJob);
}
...
}
engineJob.start方法我们会发现触发的是线程池的调用,所以直接看DecodeJob的run()方法即可,接着走到runWrapped()。
class DecodeJob<R> {
...
public void run() {
...
runWrapped();
...
}
private void runWrapped() {
switch (runReason) {
case INITIALIZE:
//初次运行执行到这里,获取资源状态
stage = getNextStage(Stage.INITIALIZE);
currentGenerator = getNextGenerator();
runGenerators();
break;
case SWITCH_TO_SOURCE_SERVICE:
runGenerators();
break;
case DECODE_DATA:
decodeFromRetrievedData();
break;
default:
throw new IllegalStateException("Unrecognized run reason: " + runReason);
}
}
private Stage getNextStage(Stage current) {
switch (current) {
case INITIALIZE:
//因为没有配置缓存策略,所以调用getNextStage(Stage.RESOURCE_CACHE),最终返回Stage.SOURCE
return diskCacheStrategy.decodeCachedResource()
? Stage.RESOURCE_CACHE
: getNextStage(Stage.RESOURCE_CACHE);
case RESOURCE_CACHE:
return diskCacheStrategy.decodeCachedData()
? Stage.DATA_CACHE
: getNextStage(Stage.DATA_CACHE);
case DATA_CACHE:
// Skip loading from source if the user opted to only retrieve the resource from cache.
return onlyRetrieveFromCache ? Stage.FINISHED : Stage.SOURCE;
case SOURCE:
case FINISHED:
return Stage.FINISHED;
default:
throw new IllegalArgumentException("Unrecognized stage: " + current);
}
}
private DataFetcherGenerator getNextGenerator() {
switch (stage) {
case RESOURCE_CACHE:
return new ResourceCacheGenerator(decodeHelper, this);
case DATA_CACHE:
return new DataCacheGenerator(decodeHelper, this);
case SOURCE:
//最终返回这个
return new SourceGenerator(decodeHelper, this);
case FINISHED:
return null;
default:
throw new IllegalStateException("Unrecognized stage: " + stage);
}
}
private void runGenerators() {
currentThread = Thread.currentThread();
startFetchTime = LogTime.getLogTime();
boolean isStarted = false;
while (!isCancelled
&& currentGenerator != null
//执行SourceGenerator.startNext()
&& !(isStarted = currentGenerator.startNext())) {
stage = getNextStage(stage);
currentGenerator = getNextGenerator();
if (stage == Stage.SOURCE) {
reschedule(RunReason.SWITCH_TO_SOURCE_SERVICE);
return;
}
}
// We've run out of stages and generators, give up.
if ((stage == Stage.FINISHED || isCancelled) && !isStarted) {
notifyFailed();
}
// Otherwise a generator started a new load and we expect to be called back in
// onDataFetcherReady.
}
...
}
看是上面代码注释,最终会走到runGenerators()中的currentGenerator.startNext(),而currentGenerator也就是SourceGenerator。到这里其实Glide的into方法已经快看了三分之一了,大家再坚持坚持,累了就喝杯水、上个厕所、朝窗外看看,休息个5分钟我们再继续。
回来我们继续看SourceGenerator的startNext()方法。
class SourceGenerator {
@Override
public boolean startNext() {
...
boolean started = false;
while (!started && hasNextModelLoader()) {
loadData = helper.getLoadData().get(loadDataListIndex++);
if (loadData != null
&& (helper.getDiskCacheStrategy().isDataCacheable(loadData.fetcher.getDataSource())
|| helper.hasLoadPath(loadData.fetcher.getDataClass()))) {
started = true;
startNextLoad(loadData);
}
}
...
}
}
主要关注helper.getLoadData(),它的作用是获取加载器,加载器,顾名思义就是决定采用何种方式来加载资源。关于加载器我们可以看下ModelLoader接口的实现类,Glide为我们提供了很多加载器。
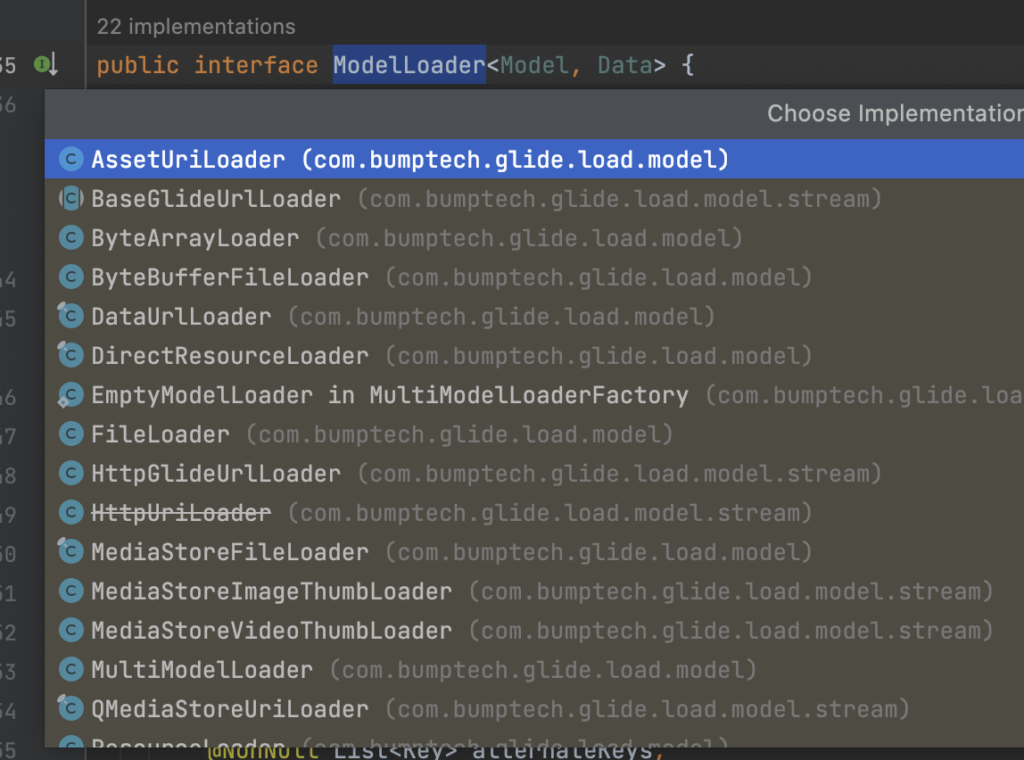
前面也提到过,getLoadData是造成Glide的into逻辑复杂的原因之一,所以这块单独用一小节来讲解。
4.2 getLoadData
同样老规矩,讲源码之前先看时序图,因为图片太大,大家下载附件看。
对照附件中的时序图以及源码,我们发现,getLoadData方法调用链路中会走到一个关键节点,就是MultiModelLoaderFactory的build方法:
public class MultiModelLoaderFactory {
private static final Factory DEFAULT_FACTORY = new Factory();
public MultiModelLoaderFactory(@NonNull Pool<List<Throwable>> throwableListPool) {
this(throwableListPool, DEFAULT_FACTORY);
}
@VisibleForTesting
MultiModelLoaderFactory(
@NonNull Pool<List<Throwable>> throwableListPool, @NonNull Factory factory) {
this.throwableListPool = throwableListPool;
this.factory = factory;
}
synchronized <Model> List<ModelLoader<Model, ?>> build(@NonNull Class<Model> modelClass) {
try {
List<ModelLoader<Model, ?>> loaders = new ArrayList<>();
for (Entry<?, ?> entry : entries) {
// Avoid stack overflow recursively creating model loaders by only creating loaders in
// recursive requests if they haven't been created earlier in the chain. For example:
// A Uri loader may translate to another model, which in turn may translate back to a Uri.
// The original Uri loader won't be provided to the intermediate model loader, although
// other Uri loaders will be.
if (alreadyUsedEntries.contains(entry)) {
continue;
}
if (entry.handles(modelClass)) {
alreadyUsedEntries.add(entry);
loaders.add(this.<Model, Object>build(entry));
alreadyUsedEntries.remove(entry);
}
}
return loaders;
} catch (Throwable t) {
alreadyUsedEntries.clear();
throw t;
}
}
private <Model, Data> ModelLoader<Model, Data> build(@NonNull Entry<?, ?> entry) {
return (ModelLoader<Model, Data>) Preconditions.checkNotNull(entry.factory.build(this));
}
}
最后我们发现是由entry.factory.build(this)这句话来创建ModelLoader的,那entry是啥?factory又是啥?看到这里可能会有点迷惑,但是不要急,我们从entry.factory入手。Entry是MultiModelLoaderFactory的内部类,factory参数是构造方法传入的。
public class MultiModelLoaderFactory {
...
private static class Entry<Model, Data> {
private final Class<Model> modelClass;
@Synthetic final Class<Data> dataClass;
@Synthetic final ModelLoaderFactory<? extends Model, ? extends Data> factory;
public Entry(
@NonNull Class<Model> modelClass,
@NonNull Class<Data> dataClass,
@NonNull ModelLoaderFactory<? extends Model, ? extends Data> factory) {
this.modelClass = modelClass;
this.dataClass = dataClass;
this.factory = factory;
}
public boolean handles(@NonNull Class<?> modelClass, @NonNull Class<?> dataClass) {
return handles(modelClass) && this.dataClass.isAssignableFrom(dataClass);
}
public boolean handles(@NonNull Class<?> modelClass) {
return this.modelClass.isAssignableFrom(modelClass);
}
}
static class Factory {
@NonNull
public <Model, Data> MultiModelLoader<Model, Data> build(
@NonNull List<ModelLoader<Model, Data>> modelLoaders,
@NonNull Pool<List<Throwable>> throwableListPool) {
return new MultiModelLoader<>(modelLoaders, throwableListPool);
}
}
...
}
构造方法是由add方法触发调用,add是由append方法触发调用,……。用语言描述难免会显得晦涩难懂,我们还是看图更直观。看到这里我们要清楚我们的目标是什么:因为我们读到entry.factory.build走不下去了,如果能找到factory具体指的是什么就能找到具体ModelLoader的创建过程。
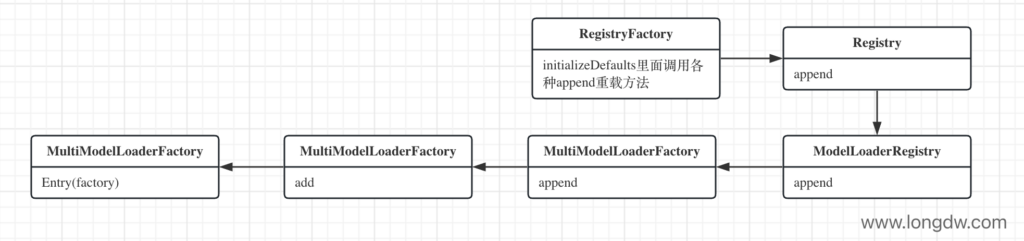
以entry.factory作为突破口,顺着Entry的构造方法,一步步的反向查找调用的链路,最终发现是由RegistryFactory的initializeDefaults方法触发调用。用同样的思路,我们发现initializeDefaults方法是在Glide初始化的过程中调用,如下:
GlideSupplier<Registry> registry =
RegistryFactory.lazilyCreateAndInitializeRegistry(
this, manifestModules, annotationGeneratedModule);
Glide通过RegistryFactory注册了很多种ModelLoader加载器,下一节讲decode解析数据也是要看这里的,因为RegistryFactory同样会注册很多解析器。
回到我们最初的问题,我们已经找到了factory参数传入的地方了,比如看下面注册的:

但是这么多加载器,怎么知道当前用的是哪个呢?
回过头看下这一节开始贴的MultiModelLoaderFactory代码,build方法中有个判断entry.handles(modelClass)。还记得我们文章开始举的例子不,我们load传入的是一个字符串,所以modelClass实际上是String.class。再结合RegistryFactory注册的ModelLoader,最后通过ModelLoaderRegister的getModelLoaders方法中的loader.handles(model)过滤,只有3个ModelLoader.Factory符合要求。
接着调用这3个Factory的build创建Loader。以StringLoader.StreamFactory()为例:
public class StringLoader<Data> implements ModelLoader<String, Data> {
private final ModelLoader<Uri, Data> uriLoader;
// Public API.
@SuppressWarnings("WeakerAccess")
public StringLoader(ModelLoader<Uri, Data> uriLoader) {
this.uriLoader = uriLoader;
}
@Override
public LoadData<Data> buildLoadData(
@NonNull String model, int width, int height, @NonNull Options options) {
Uri uri = parseUri(model);
if (uri == null || !uriLoader.handles(uri)) {
return null;
}
return uriLoader.buildLoadData(uri, width, height, options);
}
@Override
public boolean handles(@NonNull String model) {
// Avoid parsing the Uri twice and simply return null from buildLoadData if we don't handle this
// particular Uri type.
return true;
}
public static class StreamFactory implements ModelLoaderFactory<String, InputStream> {
@NonNull
@Override
public ModelLoader<String, InputStream> build(@NonNull MultiModelLoaderFactory multiFactory) {
return new StringLoader<>(multiFactory.build(Uri.class, InputStream.class));
}
@Override
public void teardown() {
// Do nothing.
}
}
...
}
build里面创建了StringLoader,其中StringLoader的构造方法又会传入一个Loader,multiFactory.build(Uri.class, InputStream.class),根据参数,再结合RegistryFactory注册的,符合要求Loader的同样有很多。
可以调试getLoadData方法来观察,最终符合要求的3个Loader如下:
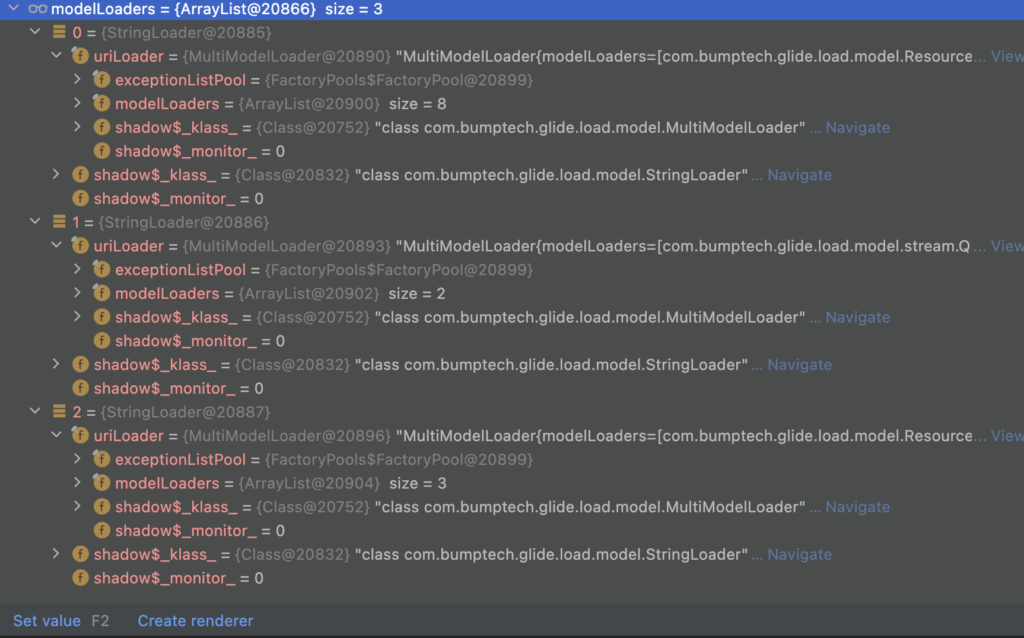
总结下,到目前为止,返回的3个Loader里面,每个Loader里面都有一个uriLoader属性,该属性类型是MultiModelLoader,每个MultiModelLoader下面又会有多个modelLoaders。
再回到getLoadData方法开始调用的地方:
final class DecodeHelper<Transcode> {
...
List<LoadData<?>> getLoadData() {
if (!isLoadDataSet) {
isLoadDataSet = true;
loadData.clear();
List<ModelLoader<Object, ?>> modelLoaders = glideContext.getRegistry().getModelLoaders(model);
//noinspection ForLoopReplaceableByForEach to improve perf
for (int i = 0, size = modelLoaders.size(); i < size; i++) {
ModelLoader<Object, ?> modelLoader = modelLoaders.get(i);
LoadData<?> current = modelLoader.buildLoadData(model, width, height, options);
if (current != null) {
loadData.add(current);
}
}
}
return loadData;
}
...
}
接着遍历返回的3个Loader,执行modelLoader.buildLoadData,实际上针对我们的例子,modelLoader就是StringLoader类型,我们翻到上面看下StringLoader的源码,buildLoadData方法里面,首先判断uriLoader.handles(uri)(这里是个分岔点,等会我们分析完handles是如何判断的之后再回到这里),uriLoader根据我们上面的分析,它实际上是MultiModelLoader类型,然后执行handles方法:
class MultiModelLoader<Model, Data> implements ModelLoader<Model, Data> {
...
@Override
public boolean handles(@NonNull Model model) {
for (ModelLoader<Model, Data> modelLoader : modelLoaders) {
if (modelLoader.handles(model)) {
return true;
}
}
return false;
}
...
}
实际上就是遍历loader并调用handles看是否符合要求。这里涉及到StringLoader嵌套MultiModelLoader,MultiModelLoader有包含各种Loader,着实让人头晕眼花,为此我也整理了下图,方便理解:
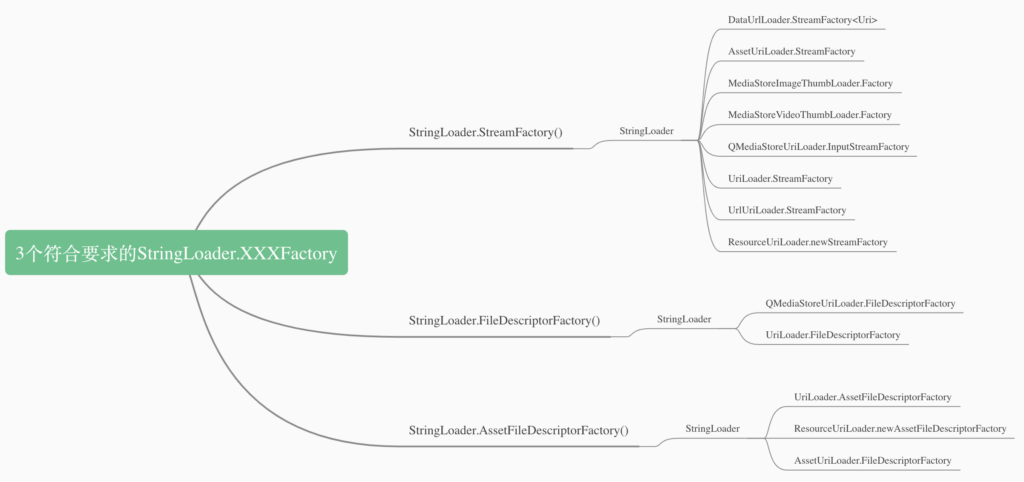
也就是说MultiModelLoader的handles方法遍历的就是这8+2+3=11个Loader,看哪个符合要求,最终调试后发现,只有UrlUriLoader符合要求。此外,刚刚是执行到StringLoader的uriLoader.handles分岔的,我们再回到这里,接着往下执行uriLoader.buildLoadData,很显然执行的是MultiModelLoader的buildLoadData方法:
@Override
public LoadData<Data> buildLoadData(
@NonNull Model model, int width, int height, @NonNull Options options) {
Key sourceKey = null;
int size = modelLoaders.size();
List<DataFetcher<Data>> fetchers = new ArrayList<>(size);
//noinspection ForLoopReplaceableByForEach to improve perf
for (int i = 0; i < size; i++) {
ModelLoader<Model, Data> modelLoader = modelLoaders.get(i);
if (modelLoader.handles(model)) {
LoadData<Data> loadData = modelLoader.buildLoadData(model, width, height, options);
if (loadData != null) {
sourceKey = loadData.sourceKey;
fetchers.add(loadData.fetcher);
}
}
}
return !fetchers.isEmpty() && sourceKey != null
? new LoadData<>(sourceKey, new MultiFetcher<>(fetchers, exceptionListPool))
: null;
}
我们刚刚分析过,目前只有StringLoader.StreamFactory创建的StringLoader,并且只有UrlUriLoader符合要求,所以很显然,我们直接看UrlUriLoader的buildLoadData方法,看看它是如何创建LoadData的。
public class UrlUriLoader<Data> implements ModelLoader<Uri, Data> {
private static final Set<String> SCHEMES =
Collections.unmodifiableSet(new HashSet<>(Arrays.asList("http", "https")));
private final ModelLoader<GlideUrl, Data> urlLoader;
// Public API.
@SuppressWarnings("WeakerAccess")
public UrlUriLoader(ModelLoader<GlideUrl, Data> urlLoader) {
this.urlLoader = urlLoader;
}
@Override
public LoadData<Data> buildLoadData(
@NonNull Uri uri, int width, int height, @NonNull Options options) {
GlideUrl glideUrl = new GlideUrl(uri.toString());
return urlLoader.buildLoadData(glideUrl, width, height, options);
}
@Override
public boolean handles(@NonNull Uri uri) {
return SCHEMES.contains(uri.getScheme());
}
/**
* Loads {@link java.io.InputStream InputStreams} from {@link android.net.Uri Uris} with http or
* https schemes.
*/
public static class StreamFactory implements ModelLoaderFactory<Uri, InputStream> {
@NonNull
@Override
public ModelLoader<Uri, InputStream> build(MultiModelLoaderFactory multiFactory) {
return new UrlUriLoader<>(multiFactory.build(GlideUrl.class, InputStream.class));
}
@Override
public void teardown() {
// Do nothing.
}
}
}
UrlUriLoader里面嵌套的urlLoader是multiFactory.build(GlideUrl.class, InputStream.class)创建的,我们找下注册表RegistryFactory,符合条件的只有HttpGlideUrlLoader.Factory(),所以接着再看HttpGlideUrlLoader。
public class HttpGlideUrlLoader implements ModelLoader<GlideUrl, InputStream> {
...
@Override
public LoadData<InputStream> buildLoadData(@NonNull GlideUrl model, int width, int height, @NonNull Options options) {
GlideUrl url = model;
...
return new LoadData<>(url, new HttpUrlFetcher(url, timeout));
}
@Override
public boolean handles(@NonNull GlideUrl model) {
return true;
}
public static class Factory implements ModelLoaderFactory<GlideUrl, InputStream> {
private final ModelCache<GlideUrl, GlideUrl> modelCache = new ModelCache<>(500);
@NonNull
@Override
public ModelLoader<GlideUrl, InputStream> build(MultiModelLoaderFactory multiFactory) {
return new HttpGlideUrlLoader(modelCache);
}
@Override
public void teardown() {
// Do nothing.
}
}
}
还记得我们的目标吗?我们的目的就是为了看下DecodeHelper中的getLoadData返回的LoadData是什么,答案就在眼前,没错,就是new LoadData<>(url, new HttpUrlFetcher(url, timeout))。终于,在经历了九九八十一难,经过了山路十八弯,终于含泪把getLoadData方法走完了。
再回到我们梦开始的地方,也就是SourceGenerator的startNext方法里面,接着往下看startNextLoad:
private void startNextLoad(final LoadData<?> toStart) {
loadData.fetcher.loadData(
helper.getPriority(),
new DataCallback<Object>() {
@Override
public void onDataReady(@Nullable Object data) {
if (isCurrentRequest(toStart)) {
onDataReadyInternal(toStart, data);
}
}
@Override
public void onLoadFailed(@NonNull Exception e) {
if (isCurrentRequest(toStart)) {
onLoadFailedInternal(toStart, e);
}
}
});
}
loadData.fetcher是什么?没错,就是HttpUrlFetcher,这个类就不贴源码了,也比较简单。主要就是使用Android最原生的HttpURLConnection来请求获取到数据流InputStream,并调用onDataReady返回,接着就执行到了onDataReadyInternal,然后回调给DecodeJob的onDataFetcherReady方法:
class DecodeJob<R> implements xxx {
...
@Override
public void onDataFetcherReady(Key sourceKey, Object data, DataFetcher<?> fetcher, DataSource dataSource, Key attemptedKey) {
...
decodeFromRetrievedData();
...
}
...
//最终执行到这里
private <Data> Resource<R> decodeFromFetcher(Data data, DataSource dataSource)
throws GlideException {
LoadPath<Data, ?, R> path = decodeHelper.getLoadPath((Class<Data>) data.getClass());
return runLoadPath(data, dataSource, path);
}
...
}
关于decodeFromFetcher,它也是造成into逻辑复杂的原因之一,我们下一小节再分析。大家先休息几分钟,喝杯水、上个厕所、朝窗外看看。
4.3 decodeFromFetcher
还是老规矩,讲源码之前先看时序图,图片太大,直接贴过来看不清,下载附件查看。
decodeFromFetcher方法里面首先调用getLoadPath创建了一个LoadPath,然后再调用runLoadPath。所以从getLoadPath这里开始分岔了,先看下LoadPath的构造方法中的参数。
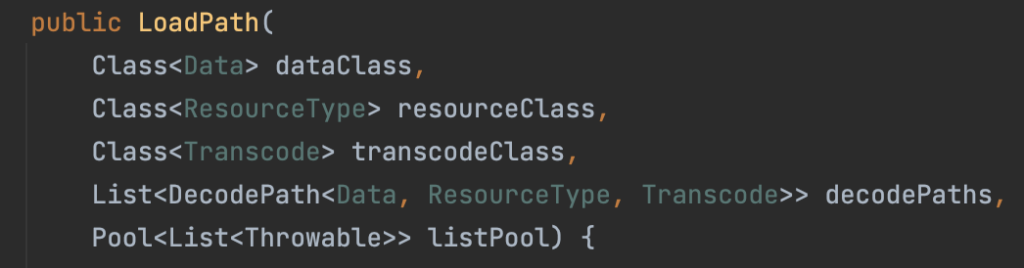
其中decodePaths参数是后面会用到的真正发起解析的,我们对照附件中的时序图,该参数的创建是在Registry的getDecodePaths方法中:
private <Data, TResource, Transcode> List<DecodePath<Data, TResource, Transcode>> getDecodePaths(
@NonNull Class<Data> dataClass,
@NonNull Class<TResource> resourceClass,
@NonNull Class<Transcode> transcodeClass) {
List<DecodePath<Data, TResource, Transcode>> decodePaths = new ArrayList<>();
List<Class<TResource>> registeredResourceClasses =
decoderRegistry.getResourceClasses(dataClass, resourceClass);
for (Class<TResource> registeredResourceClass : registeredResourceClasses) {
List<Class<Transcode>> registeredTranscodeClasses =
transcoderRegistry.getTranscodeClasses(registeredResourceClass, transcodeClass);
for (Class<Transcode> registeredTranscodeClass : registeredTranscodeClasses) {
List<ResourceDecoder<Data, TResource>> decoders =
decoderRegistry.getDecoders(dataClass, registeredResourceClass);
ResourceTranscoder<TResource, Transcode> transcoder =
transcoderRegistry.get(registeredResourceClass, registeredTranscodeClass);
@SuppressWarnings("PMD.AvoidInstantiatingObjectsInLoops")
DecodePath<Data, TResource, Transcode> path =
new DecodePath<>(
dataClass,
registeredResourceClass,
registeredTranscodeClass,
decoders,
transcoder,
throwableListPool);
decodePaths.add(path);
}
}
return decodePaths;
}
调用decoderRegistry.getDecoders创建decoders。
public class ResourceDecoderRegistry {
...
public synchronized <T, R> List<ResourceDecoder<T, R>> getDecoders(
@NonNull Class<T> dataClass, @NonNull Class<R> resourceClass) {
List<ResourceDecoder<T, R>> result = new ArrayList<>();
for (String bucket : bucketPriorityList) {
List<Entry<?, ?>> entries = decoders.get(bucket);
if (entries == null) {
continue;
}
for (Entry<?, ?> entry : entries) {
if (entry.handles(dataClass, resourceClass)) {
result.add((ResourceDecoder<T, R>) entry.decoder);
}
}
}
// TODO: cache result list.
return result;
}
...
}
又是entries、又是Entry,是不是似曾相识?没错,上一节我们讲到的getLoadData,同样也是采用类似的思路来创建的。我们也采用类似的看源码的思路,反向查找、顺藤摸瓜找到decoders赋值的地方,最终会发现同样也是在RegistryFactory中调用append方法来注册的。
看到这里我们脑海中必须得清醒点,要记住我们的目的是什么。本轮向下深入源码的目的是要找到LoadPath如何创建的以及decoders到底有哪些解析器。这是我们接下来讲runLoadPath方法的关键。
我们重点看下decoderRegistry.getDecoders方法传入的两个参数dataClass、registeredResourceClass。
首先看下getLoadPath方法传入的dataClass、resourceClass、transcodeClass。
(1)dataClass,本例中即网络请求到的数据,类型是ByteBuffer.class。
(2)resourceClass,是Object.class类型。
(3)transCodeClass,是Drawable.class类型。
我们再回到Registry的getDecodePaths方法里面。
首先registeredResourceClasses变量,根据参数类型以及对照RegistryFactory注册表,看下符合dataClass=ByteBuffer.class的有哪些,最终我们找到有如下4个符合要求。
.append(Registry.BUCKET_BITMAP, ByteBuffer.class, Bitmap.class, byteBufferBitmapDecoder) .append(Registry.BUCKET_BITMAP_DRAWABLE, ByteBuffer.class, BitmapDrawable.class, new BitmapDrawableDecoder<>(resources, byteBufferBitmapDecoder)) .append(Registry.BUCKET_ANIMATION, ByteBuffer.class, GifDrawable.class, byteBufferGifDecoder) .append(Registry.BUCKET_ANIMATION, ByteBuffer.class, Drawable.class, AnimatedImageDecoder.byteBufferDecoder(imageHeaderParsers, arrayPool));
所以最终decoderRegistry.getDecoders返回的也是这四个Decoder。
回到我们刚开始这一节的时候代码分岔的地方,接着看runLoadPath方法:
//DecodeJob.java
private <Data, ResourceType> Resource<R> runLoadPath(
Data data, DataSource dataSource, LoadPath<Data, ResourceType, R> path)
throws GlideException {
Options options = getOptionsWithHardwareConfig(dataSource);
DataRewinder<Data> rewinder = glideContext.getRegistry().getRewinder(data);
try {
// ResourceType in DecodeCallback below is required for compilation to work with gradle.
return path.load(
rewinder, options, width, height, new DecodeCallback<ResourceType>(dataSource));
} finally {
rewinder.cleanup();
}
}
首先是rewinder,跟着源码走进去,这里就不展开了,比较简单,返回的是ByteBufferRewinder。
path.load,我们对照时序图以及跟着源码走,最终走到DecodePath中的decodeResourceWithList,循环遍历4个符合要求的Decoder:
//DecodePath.java
private Resource<ResourceType> decodeResourceWithList(
DataRewinder<DataType> rewinder,
int width,
int height,
@NonNull Options options,
List<Throwable> exceptions)
throws GlideException {
Resource<ResourceType> result = null;
//noinspection ForLoopReplaceableByForEach to improve perf
for (int i = 0, size = decoders.size(); i < size; i++) {
ResourceDecoder<DataType, ResourceType> decoder = decoders.get(i);
...
DataType data = rewinder.rewindAndGet();
if (decoder.handles(data, options)) {
data = rewinder.rewindAndGet();
result = decoder.decode(data, width, height, options);
}
...
if (result != null) {
break;
}
}
if (result == null) {
throw new GlideException(failureMessage, new ArrayList<>(exceptions));
}
return result;
}
最后只有BitmapDrawableDecoder符合要求。接着调用decoder.decode,这个方法就不深入展开了,可以参照时序图来一步步的跟着源码走。
decodeFromFetcher就分析完了,最终返回的就是Resource<BitmapDrawable>类型的数据。
整个大流程的分析也快接近尾声了,最后再看下DecodeJob类中的decodeFromRetrievedData方法,拿到Resource<BitmapDrawable>后再调用notifyEncodeAndRelease方法一步步的将获取到的资源最终回调给SingleRequest的onResourceReady方法,最后调用target.onResourceReady,target在讲解into方法的整体流程的时候提到过,实际上就是DrawableImageViewTarget,最后的最后调用DrawableImageViewTarget的setResource,也就是view.setImageDrawable(resource)来设置数据。
到此为止,Glide.with(this).load(url).into(imageView)这句话所引发的各个调用链路都已经讲解完毕了。实在是太复杂了,复杂到让我不想再看第三遍了(第一遍阅读时很想放弃,但还是坚持了下来,几张时序图和流程图就是在看第一遍源码的过程中画的;写这篇博客的时候又看了一遍源码)。
阅读源码不是一蹴而就的,而且不要一行一行的读,借用郭霖有篇博客中说的:抽丝剥茧、点到即止。应该认准一个功能点,然后去分析这个功能点是如何实现的。但只要去追寻主体的实现逻辑即可,千万不要试图去搞懂每一行代码都是什么意思,那样很容易会陷入到思维黑洞当中,而且越陷越深。因为这些庞大的系统都不是由一个人写出来的,每一行代码都想搞明白,就会感觉自己是在盲人摸象,永远也研究不透。如果只是去分析主体的实现逻辑,那么就有比较明确的目的性,这样阅读源码会更加轻松,也更加有成效。
最后再贴一段扔物线大神的阅读源码的思路,值得借鉴:
- 寻找切入点,而不是逐行通读
a)理想情况下,逐行通读可以最高效率读通一个项目的代码,因为每行代码都只需要读一遍;但实时情况下,逐行通读会导致脑中积累太多没有成体系的代码,导致你读个几十几百行就读不下去了,因此一点也不实用。而从切入点开始读,可以在最快时间内把看到的代码体系化,形成一个「完整的小世界」;在把「小世界」看明白之后,再去一步步扩大和深入,就能够逐渐掌握更多的细节。
b)寻找切入点的方式:离你最近的位置就是切入点,通常是业务代码中的最后一行。
c)以 Retrofit 为例,最后的 Call.enqueue() 会被我作为切入点;再尝试从 Call.enqueue() 切入失败后,逐步回退到 Retrofit.create()方法,找到项目结构的核心,然后开始继续发散和深入。
- 在阅读过程中,始终保有把看过的代码逻辑完整化的意识
a)代码阅读过程中,不懂的代码会越来越多,脑子就会越来越乱。如果不断尝试把看到的代码结合起来组合成完整逻辑,就能让头脑始终保持清晰,而不是深入到某个细节好久之后忽然一抬头:「我为什么点进这个方法来着?」可以试着在读源码的时候,经常把多行或多段代码在脑子里(或者笔记里)组合成一整块,从而让代码结构更清晰,让阅读过程不断增加进度感,也减小继续阅读的难度。
b)以 Retrofit 为例,当读懂 Proxy.newProxyInstance() 方法实际上是创建了一个代理对象的时候,可以停下来做一个总结:「这是 Retrofit 的大框架」,在脑子里或者笔记上都可以。总结消化过后,再继续阅读。
- 尽量让每一刻都有一个确定的目标
a)读代码经常会出现「横向逻辑还没看清晰,纵向深度也没挖透」的情况。那么到底是要横向扩展阅读结构,还是纵向挖深度,最好是在每次遇到这种分岔路口的时候就先做好决定。不能在每个分岔路口都想也不想地看到不懂的就追下去,容易迷路。
b)在遇到「横向也广,纵向也深」的时候,根据情况选择其中一个就好,并没有必然哪种选择更优的铁律。而如果遇到越钻越头大的情况,可以退回之前的某一步,换条路继续走。换路的时候记得做好标记:「我在哪里探路失败了」。
本篇文章虽长,但是也只是分析了Glide的全流程,下一篇讲解Glide缓存的原理。